
Pedro Camargo, Ph.D.
Saturday, March 30, 2019
Towards efficient geoprocessing of movement data (Part 1)
By now, everybody has read (multiple times) Geoff Boeing’s excellent post on the importance of using spatial indices when performing spatial operations and the impact that having grided polygons can have in overlay operations. It is not ground-breaking, but that the number one reference I give to people that are starting in geoprocessing outside QGIS.
There are (at least) three questions, however, that Geoff left for others to respond, and I guess it was time for somebody to do just that:
- What is the impact that griding polygons has in other operations, such as point-in-polygon
- How to grid large-scale polygons
- How does the size of the grid impact the operations we are actually doing
But WAIT. What the heck does this have to do with the title of this post?
For that, we need some context…
Movement data has been the frontier in terms of data analytics challenges in transportation planning/modelling for a while. GPS data sets tend to me massive (From dozens of billions to trillions of records, each one with spatial coordinates). Microsoft’s GeoLife is an EXCELLENT dataset if you want to play with this type of data. In my case, the work involved roughly 1 million (carefully selected) points spread throughout Australia. To begin, I chose an arbitrary set of just over 45,000 points in New South Wales (NSW) and proceeded to write all the code I would need to process the larger, 1,000,000 set of points for the entire country.
The questions that I wanted to answer (and that are pertinent to this post) were mostly to do with point-in-polygon operations, as I was looking to associate land-use, statistical areas (SA), traffic analysis zones (TAZ) and other pieces of information from polygons with such points.
Now to what I was trying to do…
Even though I have written a tool in AequilibraE to do just that, i needed a to scripted way of doing this for deployment, so I did everything according to Geoff’s little example script (minus the griding of the polygon layers) and I went with GeoPandas.
Because I don’t have TAZs for the whole state, I will only show the results for the overlay between my 45,000 points and and the SA1 layer and the land use layer for New South Wales, and that should be more than enough to illustrate some of the points I am making in this post.
| Polygon layer | Number of polygons | Processing time |
|---|---|---|
| SA1 | 18,399 | 1'35" |
| Land Use | 1,043,185 | 27h49'43" |
Yeah… You read that right… over 1 day for the Land Use and just over 1.5 minutes for the SA1s. I know that the number of polygons in the SA1 layer is a couple of orders of magnitude smaller than the Land Use layer, but that should NOT translate to processing time at all. How could I expect to do this operation for a million points if I am struggling to do for 45,000?
A quick inspection of the land use layer shows that the polygons are fairly irregular, so gridding started to sound like a good idea.
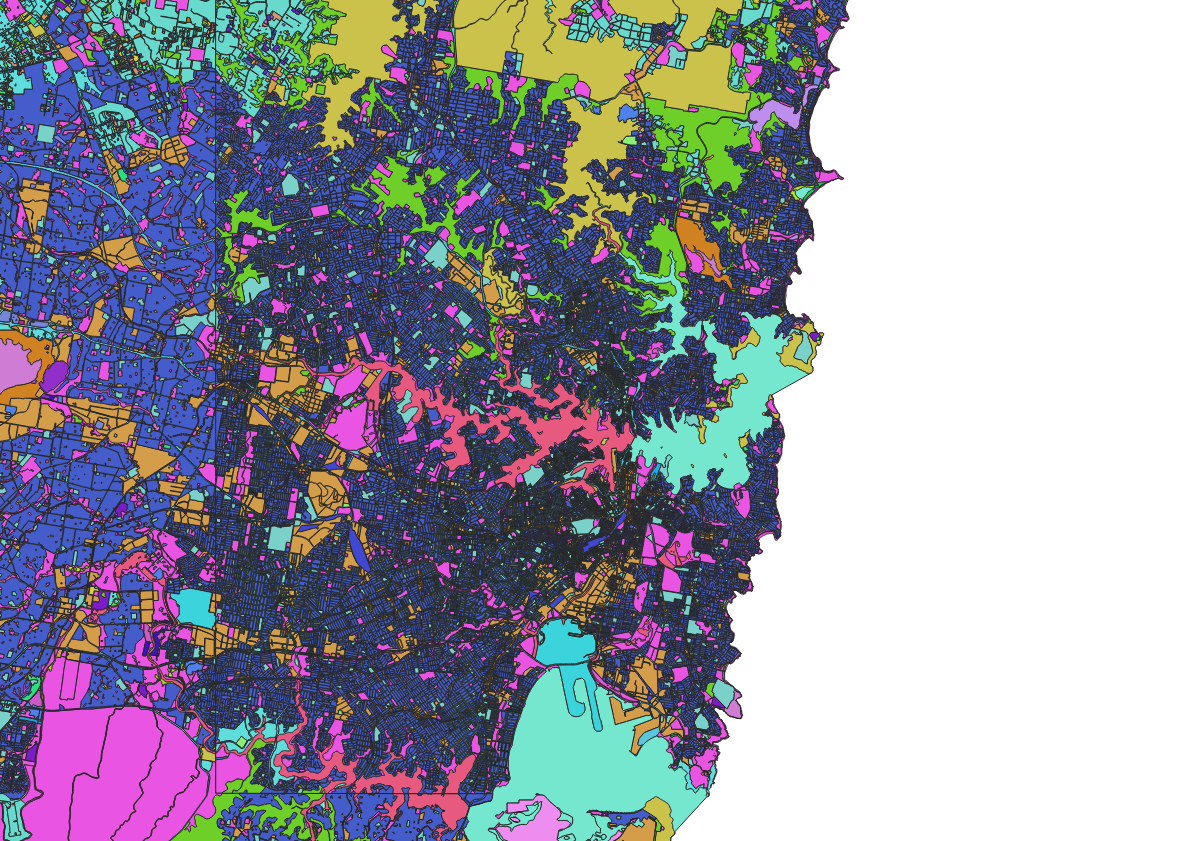
In contrast SA1s tend to have fairly regular shapes.

That brings us to the second question on our list. How does one go about gridding a polygon layer with that size and complexity?
A a grid layer, I arbitrarily chose a grid of 0.01 degrees in direction (nearly 1km side squares). More on that later.
I first started by being lazy and just going the Geopandas route…
grided_layer = gpd.overlay(land_use_layer, grid_layer, how='intersection')
That was taking too long, I also decided to do it in different ways. Just in case…
The obvious easy choice was to use the QGIS overlay tool, but that crashed almost instantly due to invalid geometries. Checking validity? That took multiple hours to run without actually fixing geometries properly, so no dice.
What about AequilibraE? I do have the Least Common Denominator tool built in for overlay exercises, so why not? Well… Even thought it was implemented with full use of Spatial indices, it took about 102h to complete its job. Incredibly easy to use, but performance is not really great…
at about databases? Spatialite or PostGIS?
Confession time!!
The reason you haven’t seen much (or any) database-related content on this blog is because I am utterly incompetent in those tools. I also find myself doing things in less-than-effective ways and spending more time on StackOverflow and debugging simple queries than it would be reasonable. However, one needs to break out of their comfort zone and admit that they need to learn something new… So PostGIS it is…
The query I used looks something like this:
CREATE TABLE grided_polygons as
SELECT nswlu.id as nswlu_id, nswlu.fid as nswlu_fid, nswlu.d_secondary as d_secondary, nswlu.d_tertiary as d_tertiary, grid.fid as grid_fid,
st_union(ST_INTERSECTION(nswlu.geom, grid.geom))
FROM nswlu, grid
WHERE ST_Intersects(nswlu.geom, grid.geom)
GROUP BY grid.fid, nswlu.id
This query was MUCH faster than anything else I had tried so far, finishing in about 19.5 h. I should be happy, but the query ran mostly (to not say entirely) as a single threaded process, which is not really great. I scavenged StackOverflow looking for some magic on leverage parallel processing, but found nothing that indicated that there was anything else I could do.
I could, however, orchestrate the parallelization from Python. Couldn’t I? If a particular segment of the slice were to be done for all polygons from id x to id y, the query would look like the following:
INSERT INTO grided_polygons
SELECT nswlu.id as nswlu_id, nswlu.fid as nswlu_fid, nswlu.d_secondary as d_secondary, nswlu.d_tertiary as d_tertiary, grid.fid as grid_fid,
st_union(ST_INTERSECTION(nswlu.geom, grid.geom))
FROM nswlu, grid
WHERE nswlu.fid> x AND nswlu.fid<= y AND ST_Intersects(nswlu.geom, grid.geom)
GROUP BY grid.fid, nswlu.id
Dividing the problem into 10,000 slices and running on all 8 threads I had available got my time down to 5h42min! That was great, but the last 40 minutes it ran a single thread, and the 2h26min prior to that it had only two slices left running. That means that for over 50% of the time it took me to process this “in parallel”, I was using at most 25% of my available logical cores. That happens before a small number of features take an inordinate amount of time to compute, and when two or three of these features end up in the same job and that job starts half way through the processing, it finishes way after all other threads were already done.
As the saying goes, in for a penny, in for a pound. So…
- How can I improve on load balancing?
- How can I better split my dataset in slices that are expected to run in the same amount of time?
To do that, I ran the gridding query one polygon at a time, recording the wall time for each query and added that to a field in the database to see if I could establish a model to predict the processing time for each feature and therefore organize them in a manner that optimized load balancing.
I had planned to use many variables in that model, including:
- Area;
- Perimeter;
- Area of the bounding box;
- Number of points in the geometry; and
- A number of linear and non-linear combinations of all of the above.
While I was setting up the Jupyter notebook with a series of linear and non-linear models to be estimated and running the necessary queries to obtain the information above (each one of them can take close to 15 minutes), it occurred to me to check if I could establish a simple rule that would provide good results without the need for the overhead of all these queries and prediction of run times.
Not surprisingly, ALL the polygons that took a non-trivial time to be processed (more than 1 minute) had a large number of geometry points to its shape. So we know that focusing on the polygons with the most shape points as sole tasks first and queuing the other polygons for later would make sense> Why not go with it?
Further, should I slice it? Or should I run one polygon at a time? It turns out that the overhead of running one polygon at a time from Python was about 10% of the overall run time, at about 21h30min, so running one polygon at a time and ensuring the best load balancing that I could sounded pretty good.
In practice, however, results were less than impressive, and processing time increased to over 8.5h by running all tasks individually, and load balancing didn’t really improve things.
There HAD to be a better way of breaking these polygons. It turns out that there is. A lovely function called ST_Subdivide. Other people have written about it in similar contexts, so although they haven’t provided performance numbers, I would take that as an indication that this is a good alternative as well.
To use this function, however, I would have to fix my polygons with another lovely function called ST_MakeValid, which removed all the self-intersections from my polygons.
I guess that, if you are working in PostGIS, running ST_MakeValid on your input data would be a basic requirement, but it is nonetheless time consuming, at about 34 minutes. It looked quite simple though…
update nswlu
set geom = st_multi(st_makevalid(geom));
It is noteworthy, however, that I ended up having to recast all my geometries as multi-polygons in order to have a single geometry type in my database (some queries require it). That, in turn, had noticeable impacts on the numbers I had just produced, as you can see in table with the full results.
The ST_Subdive query, although a bit longer (below) took only 14’45”, which was suspiciously short for somebody that had been dealing with multiple hours of run time.
CREATE TABLE nswlu_sub AS
SELECT fid, secondarya, tertiaryal, sourcescal, source, currency_d, area_ha, d_secondary, d_tertiary, ST_Subdivide(geom) AS geom
FROM nswlu;
Not that it makes sense, but can we run the griding query on top of this subdivided layer? Of course we can, and that shows that I positively had NO idea what I was doing when I started this… It took only 36’54”.
After all that, however, it was time to circle back and see if I could have done that in QGIS to start with. A few things I found:
- QGIS does have a processing tool for fixing geometries
- QGIS does have a subdivide processing tool.
- It was all there. In the geoprocessing toolbox
And not to my surprise… Subdivide took less than 5 minutes and overlay in less than 9.5h. It just blew EVERYTHING else out of the water!!!
Since I have gone that far, I decided to test a few queries in SpatiaLite as well, and although MakeValid performed pretty well, I hit a snag with a recently developed ST_Subdivide operation (could not get that to work well after compiling in my WSL, so I stopped the tests.
Putting all the results in the same place…
| Method | Processing time | Comments |
|---|---|---|
| Aequilibrae (Least Common Denominator) | ~102h | And results don’t look perfect |
| Geopandas | ?? | |
| PostGIS | ||
| Single threaded gridding | 19h28'48" | Straight from PGAdmin |
| Multithreaded gridding, 10k jobs | 5h41'43'' | Includes Python overhead in setting up jobs |
| Multithreaded gridding, one job per feature | 8h37'05'' | Includes Python overhead in setting up jobs |
| MakeValid | 33'04" | Straight from PGAdmin |
| Multithreaded gridding, 10k jobs - After MakeValid | 6h29'32" | Includes Python overhead in setting up jobs |
| Multithreaded gridding, one job per feature - After MakeValid | 9h34'40" | Includes Python overhead in setting up jobs |
| ST_Subdivide | 14'45" | Straight from PGAdmin |
| Single Threaded gridding after Subdivide | 36'54" | |
| QGIS | ||
| Gridding | 9h20'40" | It did require fixing the geometries beforehand |
| MakeValid | 16'28" | It does not convert all geometries to MultiPolygons |
| Subdivide | 4'28" | It results into multi-polygons, and one needs to use multipart-to-sin |
| Spatialite | ||
| MakeValid | 41.3" | Ran from within QGIS on Windows |
| Subdivide | ???? | Still no available, but coming soon |
In conclusion, I think there are a few takeaways from all the process I went through:
- Griding (or otherwise breaking a polygon based on other geometries) might be a nice concept, but in practice subdivide makes a LOT more sense for complex polygons
- If gridding makes sense in a future step, then subdivide-grid-merge
- PostGIS is incredibly fast when compared to non-vectorized functions in Python, but QGIS Is still king
- Whenever you cannot verify geometries in QGIS, go straight to fixing them
- QGIS outperformed PostGIS for single-threaded procedures by a huge margin
- Orchestrating parallel processing of large PostGIS queries from Python is not only possible, but also extremely effective and easy to do
- Without going through the pain of going down to C/Cython to release the GIL, it might be the best alternative to leverage multiple threads
- It will be interesting to see how to do leverage all resources in systems with large numbers of CPUS
PS1 – I know I said that this was supposed to be about point-in-polygon and movement data, but the post was already too long, so I will continue it in a second post.
PS2 – This is the longest blog post I’ve ever written, which seems to confirm that it takes a lot longer to do something when you don;t know what you are doing… 🙂
PS3 – I purposefuly did NOT play with the parameter for the Subdvide algorithms, as that is of secondary importance for this blog post
PS4 – I am just really starting with PostGIS, so let me know if I got it all wrong or if I am missing something important
PS5 – All tests were conducted on a workstation running a i7 4790k at stock clock, 32Gb of RAM and a Samsung EVO 850 SSD sATA 3