
Pedro Camargo, Ph.D.
Tuesday, March 12, 2013
Shortest Path - Djikstra in MS Excel
It was not hard to decide which would be the first post of this blog. More than an useful algorithm, it presents a good example of how simple OR tools can bring big improvements for a company’s process.
Back in 2005, when I took a course in algorithm implementation with Prof. Claudio Cunha, I was presented with a paper called “Shortest Path Algorithms” by Gallo and Pallottino. Even though this paper is quite old, it explores very well the importance of data structures on the performance of algorithms. As this paper caught my attention, I started implementing a shortest path algorithm in the two months I was between jobs (using VBA for Excel).
When I first started my job at Vale in the long term logistics planning department I found out that only a few people in the company had access to the system (a GIS layer actually) that could give precise information about the distance between two rail stations/yards, and the rest of the company was stuck with tables decades old or guestimates if they wanted to do some quick calculation in Excel. How could I plan a rail network if I did not have easy access to it’s characteristics?
Since I had to do nothing for 3 months so I could get into speed with the job (that was the rule there at that time), I decided to implement a SP algorithm using a graph based on the GIS layer available, so the whole company could have the right information about distances in the network. For my surprise the use of a C++ compiler was denied by the IT department, because software development were their job and not mine (sounds familiar?). That was actually good news, since I wouldn’t have to remember something already forgotten and would be able to/have to keep using VBA for Excel.
So I started using my paid free time to adapt my SP algorithm to the company’s rail network. It wasn’t an easy or short job, but it is sure irrelevant to my point here.
After finishing the adaptation I started working into adding more useful information to the tool I had created, like a function to be used in a cell, adding transit time between stations, station names, station cities, menus for people who use excel with the mouse, etc.
After I developed a useful tool, we sent it out to other areas and people started using slowly (people were skeptical, I think), and our department was still the heaviest user and performance started being an issue. This forced me to change the algorithm from a no data structure format (except by the forward start to keep the links) to a version where the nodes where kept in a Double-Ended-Queue and, after a couple tests, in a Min-Heap.
The improvement in performance was roughly the same to what Gallo and Pallotino present in this image (S-Ord, L-2queue, S-Heap), and the final algorithm was indeed pretty fast.
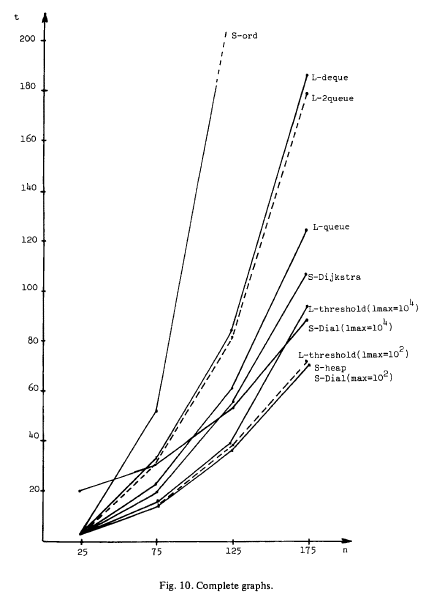
So… This was first semester of 2006, and I thought that that solution would last a couple of years until some manager noticed that it was worth it to spend a couple thousand dollars on a real and robust solution, but I heard that the company was still using the little add-on I created 5 years later.
I guess the most frustrating part is that I took time to generate a 20 pages user manual and a 10 pages update manual explaining all the bells and whistles I added (there are functions to check what is the percentage common to two OD pairs so one can check for synergy between freight flows) to this tool and I’m pretty sure nobody ever read it.
Now some of you might be asking: Why don’t he computed an SP matrix, put into a database and made a function to consult this matrix? There are a few reasons:
- It would be a LOT of data;
- It was a lot more fun to develop a 480Kb add-on that could do all that nice stuff than a 200Mb database, and tools like generating a sequence of stations/yards between an origin and a destination would not be possible;
Operations research is a tool that can and should be used with whatever computational tools are available, and even MS Excel allows you to develop and use excellent applications to improve almost any kind of business.
Finally, if any of you is interested in seeing the algorithm, I’m making the first version (with no data structure for the nodes) available HERE. The use of this tool is free for non-profitable use, but I’d like if you could tell me if you are using and give me some feedback on it. The version with the min-heap or development of specific tools/functions can be made available upon request.